Original date published: June 7, 2026
AgenticML - Designing an action serialization interface format for autonomous LLM agents
Building AgenticML, a new markup language and serialization format for LLM agents as opposed to ChatML and Harmony
AgenticML is a new markup language and serialization format for representing agent tasks as robotic execution trajectories as opposed to turn based conversation. I developed a framework for designing new serialization formats for language agents and training agents to follow custom serialization formats. The results show that while the ChatML format performs better than AgenticML on standard benchmarks such as BFCL and ToolBench, the model is fully able to execute complex multi-turn operations using this format despite not existing in the training data. While our format was more token and latency efficient, the challenge in performance stems from the representation of the evaluation set as chat turn based conversations for execution; building new evaluation formats or systems that translate standard benchmarks to custom formats would be an interesting follow up challenge. To achieve this we had to customize the model itself from the base layer, from re-embedding reserved tokens to fit our new serialization format to retraining the model itself directly from the base model without any prior supervised fine tuning or preference tuning. The work primarily uses Llama 3.1 8B base; we also explored using other models like Qwen 2.5 7B but ran into challenges accessing and customizing the reserved tokens of these models. This work shows an exciting new direction to think about how to design agentic models and a foundation to move away from turn based conversation agents to fully agentic runtime models.
Problem
The first era of language models was primarily driven around text completion, therefore most language models were used through a completion interface i.e they functioned completely within the next token prediction behaviour. As methods like RLHF and SFT developed, we were able to design models that behave like conversational assistants. This led to the release of ChatGPT as a chat based assistant model and OpenAI created the ChatCompletion interface for developers to build AI chat applications with it. This interface uses a serialization format known as ChatML (Harmony is a more recent version of ChatML but still primarily around turn based conversation); in this interface the interaction with the LLM is modeled as a chat session. The session is made of messages of one of the following types:
- System
- User
- Assistant
- Developer (This is a newer message type implemented as part of ChatML)
The natural interface for this is a chatbox, it poses the interaction with AI systems as a conversation, gradually we added more modalities to the conversation such as images and audio, but ultimately it is still based on turn based conversations.
Today, we have moved on from working with AI models as chat assistants to fully autonomous workers, these are less like turn based interactions and more like robotic mission planning and execution. Tools like Claude Code, Pi and other coding agents have made it possible to start imagining how such fully autonomous agent systems would behave, yet as agent developers we are still interacting with AI models through an interface that was designed for conversations not actions.
Chat Completion was designed for turn-taking dialogue, but agents do things that don't map cleanly to that, such as maintaining goals across long horizons, replanning as the world state changes, managing uncertainty about state, executing hierarchically (high-level intent -> mid-level plans -> low-level actions) and recovering from failures. While we can (and in many cases have) mended these challenges on the chat interface format, we are simply solving around a problem that does not need to exist anymore, which is hindering us from coming up with more innovative ideas around agentic execution.
Classical mobile robotics has decades of well-developed abstraction for those problems: the sense-plan-act loop, behaviour trees, hierarchical task networks (HTN), POMDPs, subsumption architectures, blackboard systems, ROS-style topic/service/action interfaces, and so on. The bet is that some of these would translate well into LM agents and give us a more principled interface than "stuff everything into a message list and hope".
Mobile Robotics Trajectory
Designing a new serialization interface for language agents
For the interface design itself, we are drawn to a combination of designing the runtime architecture and serialization formats (like ChatML but for agents); how do we design a token structure that would best fit agents?
Taking inspiration from robotics, we will be looking at the following methods to determine how to best design this new AgenticML interface, such as:
- Behaviour trees / HTN, which are great for structured, hierarchical task decomposition with reactive fallback
- Sense-plan-act with belief state which forces the model to maintain and update a world model, good for partial observability
- ROS-style action interface: with goal, feedback, result with preemption, this has clean async semantics
- MDP/POMDP framing which has explicit states, actions, observations, rewards, this is the most principled but heaviest to implement
- Statecharts and OODA loops
Prior works have explored this problem, but not attempted to redesign the serialization interface itself. ReAct, Reflexion, Voyager, SayCan, Inner Monologue, Tree-of-Thought, Behaviour tree structured prompting, all focus on changing the message representation interface for the agents but ultimately the data passed to the LLMs are still represented as turn based messages and therefore serialized to the model using ChatML format.
This work does not focus on building agent communication protocols like ACP, MCP, A2A. These are out of the scope of what we are trying to build here, but it would be worth exploring how these protocols can be translated to custom formats.
Thesis and Challenges
ChatCompletion is a serialization format that was retrofitted for agents. We need to design a serialization format that is native to agency, I'm calling it AgenticML. We are training a base model from scratch to operate in this format from the pretraining/post-training boundary, this is not via SFT on top of an already instruction-tuned chat model. The interface borrows load-bearing concepts from ROS and the deliberate-reactive robotics literature. RL-friendliness is a property the interface is designed natively with.
Current chat-completion-as-agent collapses all layers into a single homogenous stream. Every "turn" is the same kind of object, a message, regardless of whether it is a quick reaction, a sub-task delegation, or a full replan. That's serializing a sophisticated multi-rate control system as a flat sequence. The robotics community spent fifteen years discovering that this doesn't work and converging on layered designs. We're rediscovering this with LLMs.
For the interface design we are currently exploring 3 layers: A protocol, A runtime architecture and a Serialization method. Methods such as HBTP, BT-Gen and ReActTree all work by using BTs as an output first for LLM-based planners targeting actual robots. Nobody has proposed BTs as the native interface a general-purpose agent model is trained to operate in. The 1990 consensus in robotics is that reactive systems do not scale to long-horizon execution, yet the ReAct runtime architecture is still the most prevalent way to design autonomous agents even in advanced systems like ClaudeCode or Pegasus. The robotics community decided that a hybrid architecture consisting of a deliberative planner at the top, sequencer in the middle and reactive control at the bottom was the ideal architecture for designing robots for long task execution.
Challenges:
- Have a full understanding of the existing serialization standard and runtime
- Design a new serialization standard and runtime
- Pick a base model to build the serialization format on top of
- Create a pipeline to test training a model with the existing data pipeline
- Create synthetic data for the new training pipeline
- Run the tuning pipeline with the new agent template
- Evaluating our format on BFCL and ToolBench against existing formats like ChatML
Understanding of the existing serialization standard and runtime
ChatML typically follows a list of dictionaries called messages which forms a conversation.
This is an example of an agentic task asking the model to read a file. This is typically what the developer passes to the model and the structure the developer builds on, but what the model sees is not this json object but rather a wire sequence that is created from the tokenizer using the .apply_chat_template functionality. The wire format for this sequence would look like this.
This is the format the base model sees. The ChatML format has a set of special tokens which the model is trained to respond and interact with. They guide the model's response and also the parsers that extract the generated output from the model. The special tokens include <|begin_of_text|>, <|start_header_id|>, <|eot_id|>, <|im_start|>, <|python_tag|>. These are the tokens that the model uses to guide its response.
This serialization format is designed primarily around turn based conversation. In order to bypass the turn based conversation pattern we have to redesign our own serialization format as well.
Design a new serialization standard and runtime
A goal-native serialization format for language agents.
AgenticML is a research project exploring an alternative to chat-completion interfaces for autonomous agents. Where ChatML and Harmony treat every turn as a message with a role, AgenticML uses typed frames: goal, mission, belief, plan, think, action, result, feedback, reward, that are first-class objects in the serialization itself. Each frame is delimited by a single special token from the model's reserved vocabulary.
Rather than using conversations as used in ChatML we use trajectories, and rather than using messages we use frames. This framing alone allows us to rethink how we are interacting with these models and what we expect to get from them.
Frame types
| Marker | Owner | Payload | Purpose |
|---|---|---|---|
<|goal|> | runtime | prose | Persistent role / objective. Always the first frame. |
<|mission|> | runtime | prose | Specific task instruction. Latest supersedes earlier. |
<|obs|> | runtime | prose | Runtime context (tool definitions, env, files, etc.). |
<|belief|> | model | prose | Persistent model-internal state. Updated each step. |
<|plan|> | model | prose | Strategy. Latest supersedes earlier. |
<|think|> | model | prose | Private reasoning. Stripped after consumption. |
<|action|> | model | JSON | Tool invocation. The model may emit multiple actions per turn. |
<|end|> | model | empty | Generation stop token. Model yields control to runtime. |
<|result|> | runtime | JSON | Tool outcome. One per action. |
<|feedback|> | runtime | prose | Tool progress or user follow-up. Persistent. |
<|reward|> | runtime | number | Training-time reward signal. Stripped after consumption. |
An example trajectory in AgenticML for the same file reading task earlier would look like this
The wire format version of the sequence would look like this:
We can already see that our format is more token efficient and is training the right primitives into the model.
Pick a base model to build the serialization format on top of
For the experiment I considered the following models:
-
Qwen 2.5-7B base: Apache 2.0, openly released as base (non-instruct) checkpoints, strong pretraining, well supported in HF ecosystem and sloth
-
Olmo 2 13B base: Fully open including training data, by Allen AI. Apache 2.0 Genuinely the most scientifically clean option because you can audit what went into pretraining, slightly weaker in terms capabilities than other frontier open models but the transparency is valuable for research projects where we would like to study behaviour from pretraining to finetuning.
-
Llama 3.1 8B base: This has a less permissive license but provides the additional reserved tokens we require to run the experiment. It is also a powerful base model for experimentation. The license limitations may make it difficult for commercial applications.
I initially concluded on going with Qwen2.5-7B, but while working on the project I realized that the Qwen models do not expose their reserved tokens for modification.
Qwen2.5 doesn't include a deliberate reserve. Compared to Llama-3, where Meta documented explicitly: "we added 250 reserved tokens to support more use-cases without requiring vocab resize." That was an intentional design decision. Qwen2.5 didn't make the same choice — its special tokens are all functional (ChatML markers, vision/grounding markers, endoftext). There's no pool of pre-allocated unused slots. AgenticML requires a base model with available reserved tokens, or willingness to resize the vocabulary.
Olmo is a good research model but its performance was subpar for the projects requirements. I decided on Llama 3.1 8B base, its a strong base model with a permissive license good enough for the project. Most importantly it had enough reserved tokens that were open to modification.
Here is an example of the wire format used in the instruction tuned version of Llama 3.1.
We will be training the model to use our own AgenticML format as opposed to this default format.
Design decisions
- Base model: Llama-3.1-8B-base. Llama-3 has 250 documented reserved
special tokens; Qwen2.5 does not. AgenticML claims eleven of these
reserved slots and aliases them to frame markers at the string level:
AgenticML marker Reserved token Token ID <|goal|><|reserved_special_token_0|>128002 <|mission|><|reserved_special_token_1|>128003 <|obs|><|reserved_special_token_2|>128005 <|belief|><|reserved_special_token_3|>128011 <|plan|><|reserved_special_token_4|>128012 <|think|><|reserved_special_token_5|>128013 <|action|><|reserved_special_token_6|>128014 <|end|><|reserved_special_token_7|>128015 <|result|><|reserved_special_token_8|>128016 <|feedback|><|reserved_special_token_9|>128017 <|reward|><|reserved_special_token_10|>128018 - No closing tokens. Each frame extends until the next marker or
<|end|>. <|end|>is a stored frame and generation stop. Each model turn ends with an explicitendframe in the trajectory; the model emits<|end|>to yield control to the runtime.- Batched actions per turn. A model block may emit multiple actions; the runtime emits a result for each, in order.
- No action IDs in v1. Action-result correspondence is positional.
- TypeScript-namespace tool schemas (Harmony-style). The model has seen this format in pretraining.
- Strict ownership at the parser. Model output cannot contain runtime-owned frames in strict mode.
- Tool schemas are caller-owned. Use
with_tool_obs(trajectory, tools)once beforestep();step()tokenizes the trajectory as given.
Create a pipeline to test training a model with the existing data format
To test the validity of our approach we would be testing on both a base model trained on ChatML and a base model trained on AgenticML. This would give us a platform to make a fair comparison between both approaches.
Before training the base model, because the reserved tokens were not used at all during training we would have to initialize them. We are performing two primary activities during the initialization phase. Firstly we are trying to update the tokenizer to use our template. Secondly we are updating the input and output embeddings of the decoder model to be more familiar with our format by applying the mean of internal representations of related words as the starting point embedding for our model. We do this for both the ChatML and AgenticML format.
Once the initialization is complete we push the initialized versions of the models to the hub. This is what we will use as the base versions we would be training on top of. You can find the initialized versions of the Llama 3.1 8B model I created from AgenticML and ChatML on huggingface.
Create synthetic data for the new training pipeline
The entire training process is done on synthetic data. I created a synthetic data generation pipeline that generates accurate agentic trajectories using Qwen 3.5 Plus. The trajectories are generated in the following domains:
| Domain | Share | Slug |
|---|---|---|
| Coding and dev tools | 12% | coding |
| Personal finance | 8% | finance |
| Scheduling and calendar | 6% | scheduling |
| Cooking and meal planning | 6% | cooking |
| Research and fact synthesis | 8% | research |
| News and current events | 4% | news |
| Travel planning | 6% | travel |
| Writing and communication | 8% | writing |
| Tutoring and education | 6% | education |
| Health information | 4% | health |
| Home and household ops | 4% | home |
| Smart home / IoT | 4% | smart_home |
| Shopping and gifts | 4% | shopping |
| Music and media curation | 4% | media |
| Photo and file curation | 3% | photo |
| Interpersonal advice | 3% | interpersonal |
| Legal and contract review | 3% | legal |
| Vehicle / repair diagnosis | 2% | vehicle |
| Civic / non-profit / charity | 3% | civic |
| Customer support | 2% | support |
We use a crafted prompt and a parallel generation pipeline to generate the dataset in the AgenticML format. We then write a follow on script to convert the trajectories into ChatML which is what would be used in training the base ChatML model for comparison. Once completed I pushed the training data to the huggingface hub which can serve as a foundation for future work, the dataset can be found here.
Run the training pipeline with the new agent template
For training here is how we setup our experiment configuration and objectives:
Experimental Setup
| Item | Value |
|---|---|
| Base | Llama 3.1 8B |
| Data | kosiasuzu/agenticml-agent-trajectory-dataset (frames / messages paired) |
| Init | Reserved-slot embeddings (AgenticML) vs instruct tokenizer rows (ChatML) |
| Training | LoRA r=32, α=64, 2 epochs, cosine LR 2e-4, batch 1 × grad accum 32 |
| Models | agenticml-llama3.1-8b-lora-merged, chatml-llama3.1-8b-lora-merged |
| Pod | RunPod w7ldz9cztwcljf, NVIDIA L40S |
| Command | agenticml eval-run-all --suites bfcl toolbench format_validity --continue-on-error |
| BFCL subset | 45 pinned IDs in src/agenticml/evaluation/benchmarks/bfcl/subset.py, seed 42 |
| ToolBench subset | 10 pinned G1_instruction query IDs in toolbench/subset.py |
Research Questions
- RQ1 — Format Validity: Can each format produce parseable, structurally valid agent output?
- RQ2 — Downstream benchmarks: Does serialization affect BFCL / ToolBench under matched SFT?
- RQ3 — Efficiency: Token and latency cost per successful BFCL task?
Here is a code snippet of the training configurations we used for the LoRA training of both models.
We trained both the AgenticML model and ChatML model on the full datasets and each took about 2.5 hours on an L40S GPU.
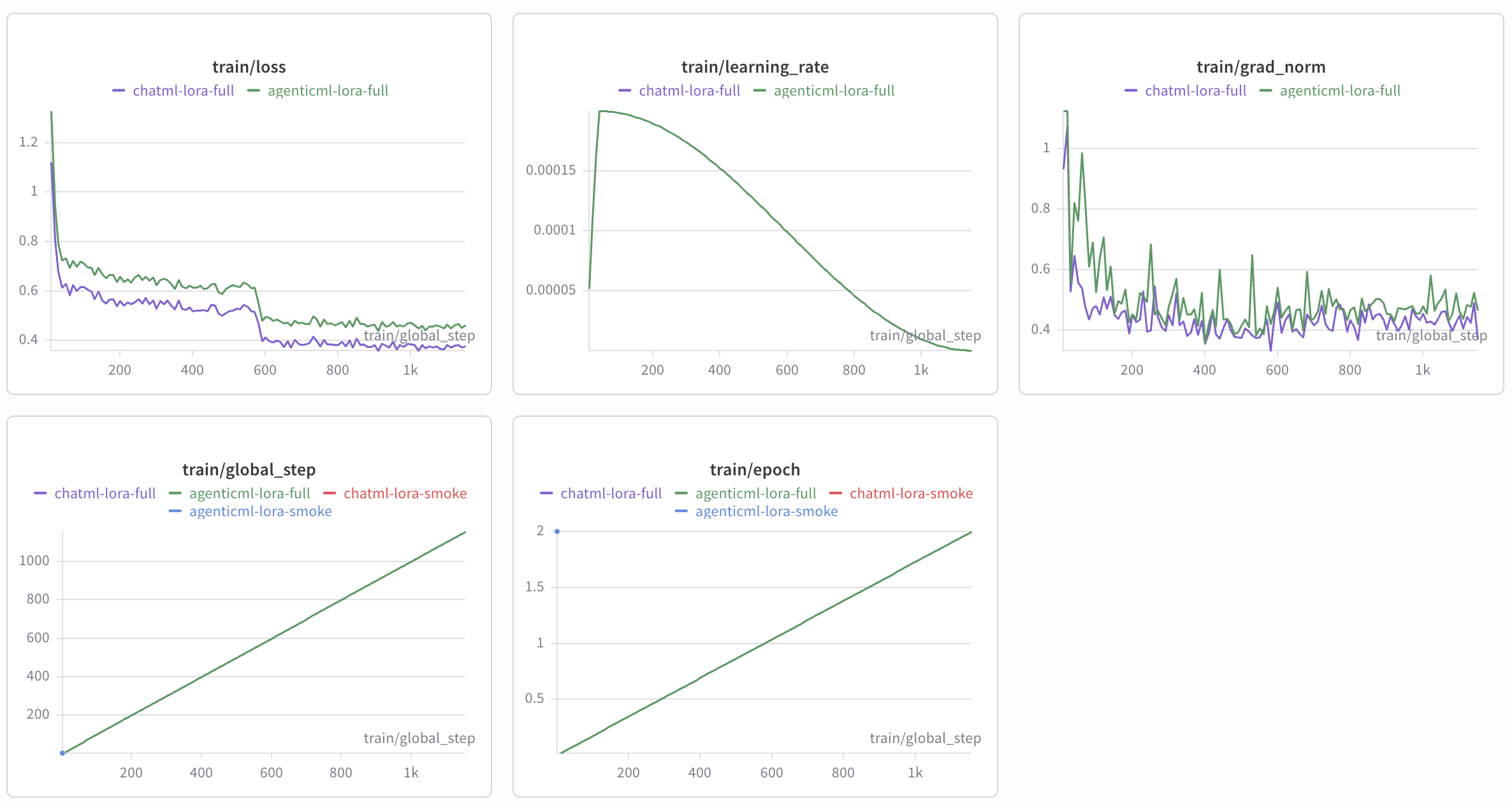
AgenticML & ChatML Training
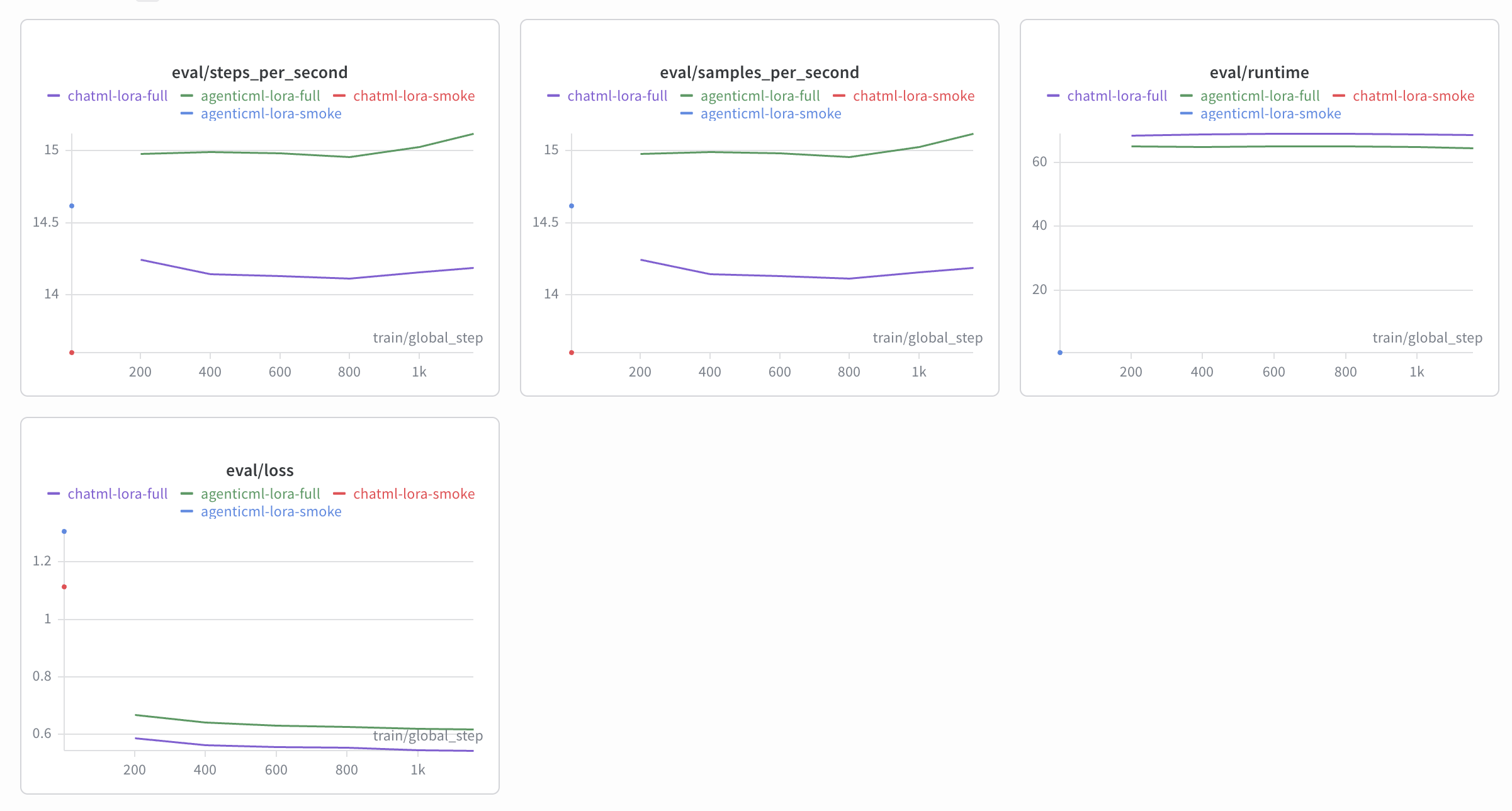
AgenticML & ChatML Evaluations
Once the models were trained I pushed both to the huggingface hub. The AgenticML model and the ChatML model. We also deployed the LoRA adapters here and here.
Evaluating our format on BFCL and ToolBench against existing formats like ChatML
We built evaluation sets on top of ToolBench, Berkeley Function Calling Leaderboard (BFCL) and SWEBench-Mini. These benchmarks were chosen because they are representative benchmarks of agentic tasks. I had to drop SWEBench-Mini due to the large computational requirements needed to run it, so I focused on ToolBench and BFCL. I had to write custom bridges for the evaluations and scoring algorithms to map the ChatML format used by the evaluation benchmarks to the AgenticML format. We also created a formality verifier bench to ensure the trained models were outputting responses in the correct format. Here are the results of the experiments.
| Suite | Format | Model | n | Primary | Secondary | Avg Tokens | Tok/Success | Avg Wall Sec |
|---|---|---|---|---|---|---|---|---|
| BFCL | AgenticML | agenticml-llama3.1-8b-lora-merged | 45 | 4.4% (accuracy) | 3.9 (avg_retry_count) | 140,018 | 1,363 | 223.9 |
| BFCL | ChatML | chatml-llama3.1-8b-lora-merged | 45 | 60.0% (accuracy) | 1.6 (avg_retry_count) | 14,268 | 3,775 | 3.9 |
| ToolBench | AgenticML | agenticml-llama3.1-8b-lora-merged | 10 | 0.0% (pass_rate) | 1.0 (avg_steps) | 2,121 | — | 29.7 |
| ToolBench | ChatML | chatml-llama3.1-8b-lora-merged | 10 | 0.0% (pass_rate) | 9.8 (avg_steps) | 21,542 | — | 11.4 |
| Format Validity | AgenticML | agenticml-llama3.1-8b-lora-merged | smoke | 100% (valid_rate) | 100% (parse_rate) | — | — | — |
| Format Validity | ChatML | chatml-llama3.1-8b-lora-merged | smoke | 100% (valid_rate) | 100% (parse_rate) | — | — | — |
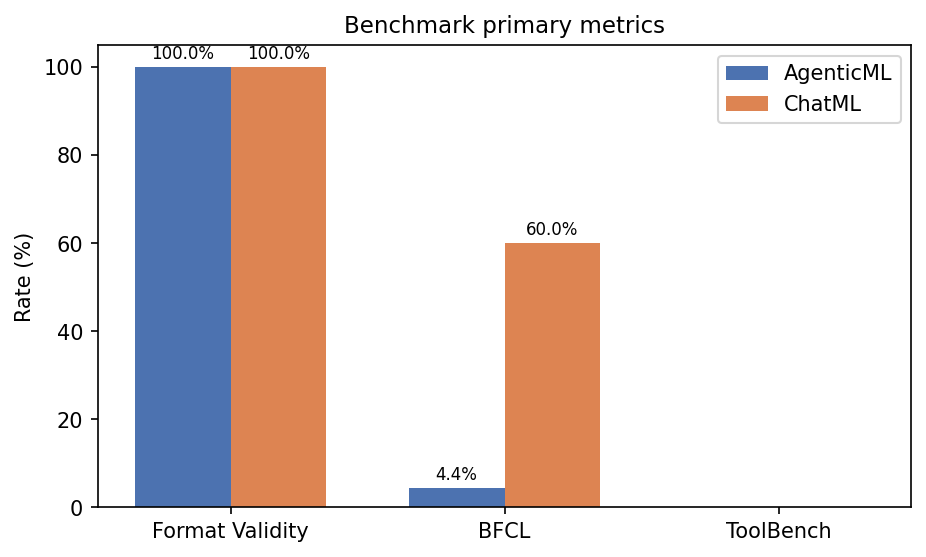
Suite Primary Metrics
Here is the break down of BFCL by category
| Category | AgenticML | ChatML |
|---|---|---|
| simple_python | 0/12 | 12/12 |
| multiple | 0/4 | 4/4 |
| parallel | 0/4 | 0/4 |
| parallel_multiple | 2/4 | 0/4 |
| live_simple | 0/7 | 4/7 |
| live_multiple | 0/6 | 6/6 |
| multi_turn_base | 0/8 | 1/8 |
Here is a breakdown of the failures in BFCL
43 failed tasks:
| Shape | Count | Meaning |
|---|---|---|
| json_tool_call | 28 | Model emitted tool JSON; BFCL grader still rejected |
| multi_turn_all_empty | 8 | No usable turn output across multi-turn loop |
| empty_no_tool_call | 7 | Encoded result was [] |
This is a breakdown of the failure modes for AgenticML on the evaluation
- Duplicate parallel arrays on single-call tasks — e.g.
simple_python_52,_57,_71,_114. Ground truth expects one{"name": ..., "parameters": ...}. Multiple action frames in one step →actions_to_resultbuilds a JSON array. ChatML emits a single FC object → 12/12 on simple_python. - Multi-turn collapse (0/8) — Loop stops when a step returns
[]or parse error. - Live schema mismatch (0/13 AgenticML vs 10/13 ChatML) — Live categories need exact dotted tool names; ChatML uses BFCL’s native system prompt; AgenticML uses goal/mission + TypeScript
with_tool_obs. - Parallel categories — ChatML often emits one call when several are required; AgenticML sometimes over-calls.
parallel_multiple2/4 is the one category where AgenticML beat ChatML.
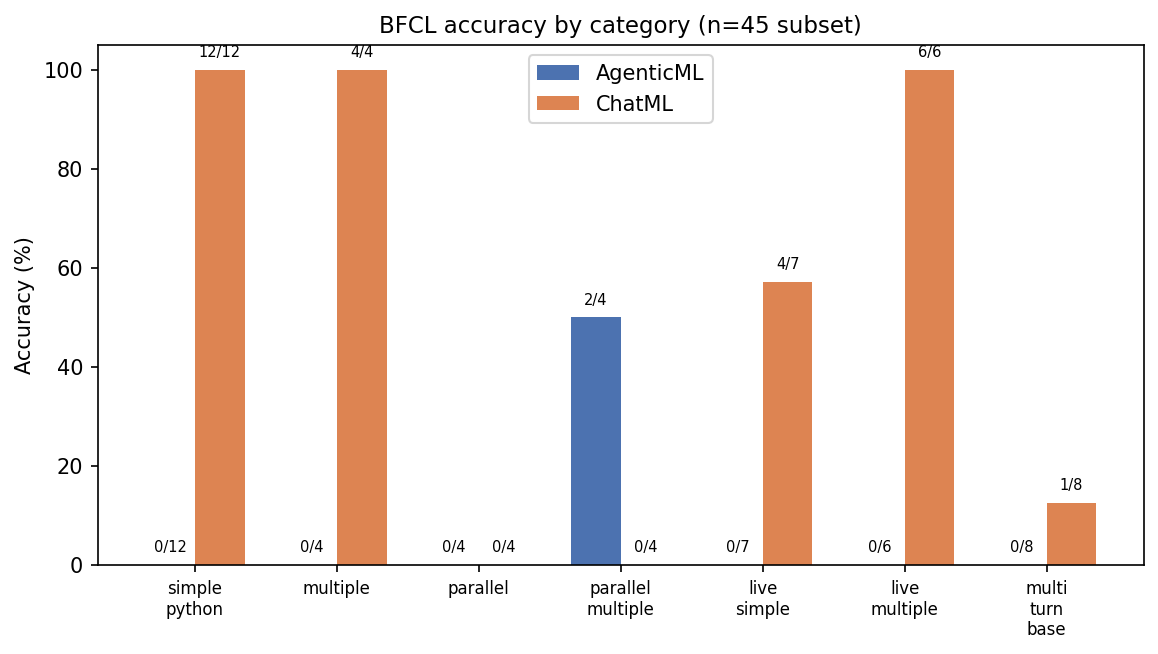
BFCL Failure per Category
All 10 ToolBench tasks completed inference and scoring. Every row failed structurally with no finish (no terminal finish action within step budget). Infra is fine; models need better multi-step tool use on G1_instruction.
AgenticML BFCL runs averaged 140k tokens and 224s wall time per task vs ChatML 14k tokens and 3.9s — largely driven by retry loops and multi-turn empties, not raw inference speed alone.
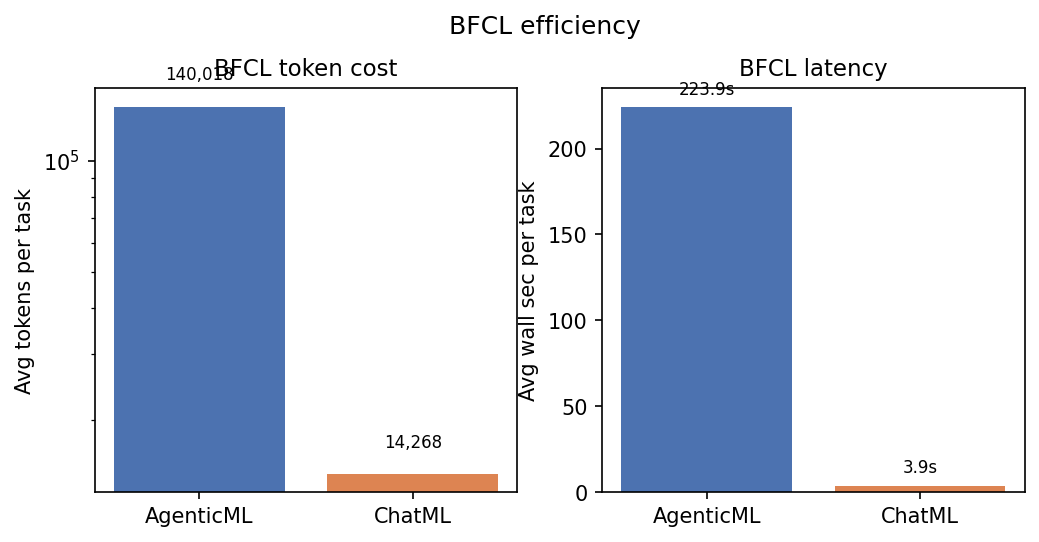
BFCL Efficiency Comparison
Conclusion
While I did not get the results I was expecting I think this serves as a foundation to a new approach in thinking of how we build agentic models. With more compute resources I would be able to pursue some of these gaps in performance of the AgenticML format, and explore how to build custom evaluations for AgenticML and convert existing evaluations in ChatML into the AgenticML format for fairer evaluations. Here are some brief AI generated takeaways from the work so far:
Prompt alignment vs BFCL: ChatML eval uses BFCL’s native ChatML + function-call path. AgenticML uses our frame runtime and bridge into gorilla result JSON. That asymmetry is intentional (each format evaluated in its natural harness) but it explains much of the live-category gap.
Eval fairness: Treating AgenticML 4.4% as pure capability understates the format. A harness fix (single-call collapse for non-parallel categories) is the highest-leverage ablation before retraining.
When AgenticML may still help: Trajectory clarity, custom runtimes, SWE-style long horizons, domains where ChatML FC is not the target wire format.
Limitations: 8B only; synthetic data; Format Validity not at n=100 on RunPod; SWE-bench skipped; no harness-fix ablation yet; ToolBench 0% both formats.
The entire code repository of the work can be found here https://github.com/asuzukosi/agenticml